
Wenn wir über Verfahren der Bibliometrie sprechen, dann meinen wir, vereinfacht gesagt, die Anwendung statistischer Methoden auf bibliographische Daten. Die Ergebnisse bibliometrischer Verfahren und Analysen erlauben Rückschlüsse auf die Korrespondenzen wissenschaftlicher Publikationen untereinander oder auf die relativen und absoluten Häufigkeiten der Zitation. Beides ist im Interesse der Wissenschaft und entsprechend sind diesbezügliche Indizes von großem Wert für die wissenschaftliche Community. Eugene Garfield, einer der Mitbegründer der Bibliometrie, verweist hierauf in einem tonangebenden Artikel von 1955: “It would not be excessive to demand that the thorough scholar check all papers that have cited or criticized such papers, if they could be located quickly. The citation index makes this check practicable.” (Garfield, E. (1955). Citation Indexes for Science. A New Dimension in Documentation through Association of Ideas. Science, 122(3159), 108-111.
Der hier formulierte Anspruch auf Sorgfalt und Reproduzierbarkeit von wissenschaftlichen Ergebnissen führte zu unterschiedlichen Verfahren der Messung von wissenschaftlicher Reichweite und Relevanz (“Impact”). Ich möchte deren Grundzüge nachfolgend kurz darstellen und dann problematisieren, wie sich deren Handhabung verselbständigt hat, welcher Fehlschluss vorliegt und welche Alternativen es gibt.
Bibliometrische Verfahren als quantitative Vermessung
Bibliometrie meint also das systematische und kontrollierte Zählen von Zitationen und damit die Messung der Reichweite wissenschaftlicher Publikationen. Das kann auf verschiedenen Ebenen geschehen und entsprechend verschiedene Metriken zur Folge haben: Auf Artikel-Ebene (z.B. in der Public Library of Science), auf Zeitschriften-Ebene (z.B. Journal Impact Factor, kurz “JIF”) und auf Ebene der Autor*innen (z.B. h-Index). Den jeweiligen Metriken liegen unterschiedliche Verfahren zur Datenaggregation und -analyse zugrunde, d.h. die jeweiligen Daten werden aus unterschiedlichen bibliograpischen Datenbanken abgerufen und mit bestimmten Methoden betrachtet und ausgewertet (z.B Citation Graphs). Nicht zu unterschätzen ist in diesem Feld der Einfluss großer Verlage und kommerzieller Dienstleister: Wichtige Metriken wie der Journal Impact Factor basieren auf dem Web of Science und damit einer Datenbank von Clarivate Analytics; ähnlich berechnet sich CiteScore aus Scopus, einer Datenbank, die von Elsevier betrieben wird.
Das Prinzip ist stets ähnlich: Über eine quantitative Vermessung können wir angeben, wie oft ein Artikel oder ein*e Autor*in zitiert wird oder wie viele Artikelzitationen eine Zeitschrift hat. Damit machen wir Angaben über die Reichweite des Artikels, der Zeitschrift oder des Autors, jedoch nicht über die tatsächliche Qualität einer Publikation, eines Publikationsortes oder eines Autors. Zugleich werden diese Statistiken und Reichweitenmessungen aber in bestimmten Situationen als Instrument der Qualitätsmessung verwendet, etwa in der Auswahl von Bewerber*innen für eine Stelle, bei der Auswahl kanonischer Zeitschriften einer Disziplin oder bei der Vergabe von Forschungsförderung. Nun braucht es gewiss bestimmte Instrumente, Verfahren und Filter, um – wie auch Garfield bemerkte – bei der steigenden Zahl von Publikationen und Ausdifferenzierung von Themen einen sachgemäßen Überblick zu behalten. Aber warum ist nun zur Vorsicht geraten, wenn wir qualitative Rückschlüsse aus bibliometrischen Analysen ziehen?
Problem 1: Unterschiedliche Datenbanken haben unterschiedliche Abdeckungen
Metriken speisen sich aus unterschiedlichen Datenbanken, die eine zum Teil gravierend unterschiedliche Abdeckung aufweisen. Die Abbildung verdeutlicht diese Unterschiede in der Gesamtmenge sowie in der Überschneidung für Scopus, Web of Science, Dimensions, Crossref und Microsoft Academic.
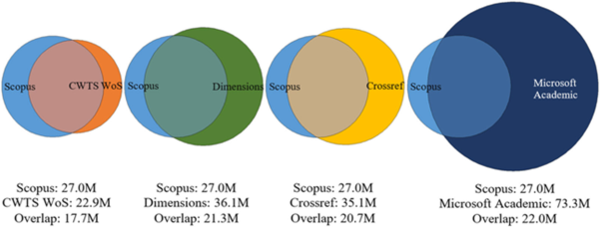
Kongruenz bibliographischer Daten in ausgewählten Datenbanken
Visser, M., Van Eck, N. J., & Waltman, L. (2021). Large-scale comparison of bibliographic data sources: Scopus, Web of Science, Dimensions, Crossref, and Microsoft Academic. Quantitative Science Studies, 2(1), 20–41.
Nun gehen etwa Web of Science und Scopus bei der Aufnahme von Daten äußerst selektiv vor, was laut Eigenaussage der jeweiligen Betreiber ein Indiz für die Qualität der jeweiligen Daten sein soll. Die Kriterien für die Inklusion lohnen einer weiteren Betrachtung, dazu später mehr.
Problem 2: Metriken sind manipulierbar
Wie sich einschlägige Metriken berechnen, d.h. die jeweiligen Formeln und die jeweiligen Datengrundlagen, sind bekannt oder leicht zu recherchieren. Nehmen wir das Beispiel des Journal Impact Factor: Der JIF einer Zeitschrift X im Jahr 2023 errechnet sich aus den Zitationen in 2023 (laut Web of Science) all jener Artikel, die in dieser Zeitschrift in 2021-2022 publiziert wurden, geteilt durch die Anzahl von Artikeln (sofern zitierbar, nach WoS), die in dieser Zeitschrift in 2021-2022 publiziert wurden. Dabei wird ein hoher JIF als “besser” gewertet, d.h. eine möglichst hohe Anzahl von Zitationen bei möglichst geringer Anzahl an Artikeln.
Der JIF ist unter anderem so bekannt, weil er als Qualitätsmaßzahl wahrgenommen wird und einfach zu erschließen ist. Dadurch wird der JIF, aber auch andere Metriken, anfällig für eine bewusste Einflussnahme durch Akteur*innen mit fragwürdigen Intentionen und schließlich der ohnehin begrenzte Nutzen eingeschränkt (vgl. das sog. “Impact Factor Game”, also die gezielte Beeinflussung des JIF). Diese Einsicht in die Beeinflussbarkeit von Metriken führt zwar zu mehr und mehr öffentlicher Kritik (vgl. die Kritik der San Francisco Declaration on Research Assessment am h-index). Die Popularität der Metriken im Publikationsmainstream scheint aber ungebrochen.
Problem 3: Inklusionskriterien für einschlägige Indizes sind intransparent
Wichtige Metriken wie der Journal Impact Factor errechnen sich aus den Datensätzen großer Datenbanken von zumeist kommerziellen Anbietern. Die Metriken und ihre Datengrundlage beruhen dabei auf Kriterien und Vorannahmen, die jeweils für spezifische Kontexte gelten, aber deren Anwendbarkeit für das Wissenschaftssystem insgesamt nicht unbedingt einsichtig sind. So kann das 2-Jahres-Fenster des Journal Impact Factors für dynamische Disziplinen durchaus angemessen sein, für traditionell langsam publizierende Disziplinen wäre aber durchaus über eine Erweiterung des Fensters nachzudenken. Darüber hinaus sind die eigentlichen Kriterien für die Inklusion von Zeitschriften in den einschlägigen Datenbanken unklar: Zwar gibt es etwa im Web of Science einen mehrstufigen, strukturierten Antragsprozess, um bestimmte Qualitätsparameter früh abzufragen. Die eigentliche Entscheidung zur Aufnahme liegt aber bei Clarivate Analytics.
Schließlich, und das unterscheidet die einschlägigen Datenbanken kommerzieller Anbieter etwa von OpenAlex (https://openalex.org/), sind die vollständigen Datensätze und damit Grundlagen der Berechnung nicht oder nur sehr umständlich einsehbar oder datierbar. Es wäre entscheidend für eine verantwortungsvolle Beurteilung des Werts von Reichweitenmessungen, wenn sie reproduzierbar oder für die Wissenschaft mindestens nachvollziehbar wären.
Auch wenn die vorgenannten Probleme nicht erschöpfend die Kritik an bestimmten metrischen Verfahren behandeln – die Literatur hierzu ist mannigfaltig –, so schlussfolgerten schon 2006 etwa die PLoS Medicine Editors: “We conclude that science is currently rated by a process that is itself unscientific, subjective, and secretive.” (The PLoS Medicine Editors. (2006). The Impact Factor Game. PLoS Medicine, 3(6), e291.).
Neben all der berechtigten Kritik gibt es aber auch diverse produktive Vorschläge aus unterschiedlichen Kontexten, um das System der Forschungsevaluation zu reformieren und aus seiner Abgeschlossenheit zu öffnen.
Vorschläge für eine andere Bewertung
Voraussetzung für eine offene Forschungsevaluation ist offenkundig der freie Zugang zu den zugrundeliegenden Forschungsinformationen. Schon 2012 hat die San Francisco Declaration on Research Assessment zur Datentransparenz bei der Metriknutzung für alle Stakeholder aufgerufen und damit wichtige Pionierarbeit in diesem Bereich geleistet. Jüngst sekundierte die Barcelona Declaration on Research Information (2023) den Offenheitsgedanken und insistierte auf Open Source und Interoperabilität für Forschungsinformationen. Die Coalition for Advancing Research Assessment (CoARA) führt schließlich unterschiedliche Bemühungen in Form von Aktionsplänen, Arbeitsgruppen und Prinzipien zusammen.
Eine vielfach vor diesem Hintergrund diskutierte, alternative Möglichkeit ist die Rückkehr auf die qualitative Bewertung einzelner Publikationen, statt die quantitative Messung der Reichweite. So könnte bei Bewerbungen und Berufungen von den jeweiligen Kandidat*innen eine geringe Zahl von Publikationen hervorgehoben und nur diese von Gutachter*innen bewertet werden. Die DFG geht seit März 2023 in eine vergleichbare Richtung, wenn sie in den standardisierten Lebensläufen zur Antragseinreichung eine Auswahl, statt die Gesamtliste der Publikationen der Antragstellenden fordert (vgl. DFG-Vordruck 1.91 – 03/25 “Hinweise zu Publikationsverzeichnissen”).
Eine weitere Möglichkeit ist es, den Raum der Reichweitenmessung zu erweitern. Wie zuvor gezeigt, wollen alle Metriken einen angenommenen Impact messen. Jedoch hängen Reichweite und Impact stets vom Raum der Messung ab. So genannte Alt-Metriken erweitern diese Räume, indem sie alternative Indikatoren mit einbeziehen. Soziale Medien und offene Datenbanken werden (meist DOI-basiert) einbezogen, was die Abschätzung der Reichweite eines Forschungsbeitrags validieren kann. Selbstredend hat diese Erweiterung eine Schattenseite: Diese Alt Metric Scores hängen stark von den Aufmerksamkeitsmechanismen sozialer Medien und den Entscheidungen der dahinterstehenden Unternehmen (wie X, Meta) ab.
Schließlich, und dieser Vorschlag ist vielfach wiederholt, müssen die vorhandenen Open-Access- bzw. Open-Science-Policies mit den jeweiligen Praktiken der Evaluation vereinbart werden. Sprich: Wird bei Auswahlverfahren auf Qualität statt Quantität geachtet? Sind die entsprechenden Komitees über die Empfehlungen zur alternativen Evaluation informiert?
Insbesondere dieser letzte Vorschlag verweist auf die Selbstwirksamkeit der “scientific community” – denn derartige Veränderungen können nur von und aus der Wissenschaftsgemeinde selbst kommen.
Dieser Beitrag basiert auf einem Vortrag am 24.09.2024 beim 29. Wissenschaftlichen Kongress der DVPW in Göttingen.
Über den Autor:
Marcel Wrzesinski ist Associated Researcher am Alexander von Humboldt Institut für Internet und Gesellschaft und Co-Sprecher des scholar-led.network.
Über die Rubrik "Pollux. Für die Politikwissenschaft"
In der Rubrik “Pollux. Für die Politikwissenschaft” berichtet das Team vom Fachinformationsdienst (FID) Politikwissenschaft - Pollux regelmäßig von neuen Angeboten und Entwicklungen aus den Bereichen Literaturrecherche, Open Access, Forschungsdatenmanagement, Wissenschaftskommunikation und weiteren Themen, die Informationsinfrastrukturen betreffen. Wir freuen uns über Ihre Rückmeldungen, Anregungen, Fragen und Kritik an kontaktpollux-fidde.
Mehr Informationen unter: www.pollux-fid.de
Aktuelles bei Bluesky fidpol.bskysocial und Mastodon fidpol@polsci.social
Anmeldung zum Newsletter: https://www.pollux-fid.de/newsletter